1)subquery
1-1) 단일행 subquery
1-2)복수행 subquery
1-3) 다중컬럼 subquery
1-4)상호연관 subquery
1-5) inline view subquery
2)DDL(데이터정의어)
2-1)자료형 ( mariaDB)
2-2)DDL 특징
2-3) create
2-4)alter
1)ALTER 컬럼 수정
1-1)컬럼 추가( ADD)
1-2)컬럼변경( MODIFY)
1-3)컬럼 삭제( DROP)
1-4)컬럼 변경( CHANGE)
1-5)ALTER 컬럼 수정 정리
2)alter 제약조건 수정
2-1) 기본키 설정
2-2) 외래키설정
3) 예제
1) @@ subquery @@
subquery : select 구문내에 select구문이존재
where조건문에서 사용되는 select구문
1-1) 단일행 subquery
subquery 가능부분
select 문
where 조건문 : subquery
from : inline 뷰
컬럼부분 : 스칼라 subquery
사용예시)
-- emp 테이블에서 김지애 사원보다 많은 급여를 받는 직원의정보조회
-- 1. 김지애직원급여 조회
SELECT salary
FROM emp
WHERE ename = '김지애'; #김지애의급여 550
#subquery를 활용
SELECT ename , salary
FROM emp
WHERE salary>( SELECT salary #이 select문의 결과는 salary(550)이다
FROM emp
WHERE ename = '김지애');

-- 문제
-- 김종연 학생보다 윗학년의 이름과 , 학년 ,전공번호1 , 학과명출력
SELECT s.grade , s.NAME , s.major1 , m.name
FROM student s JOIN major m #학과명을 얻기위해선 major테이블과조인
ON s.major1 = m.code
WHERE grade>( # 김종연 학생의 학년을 select한 subquery 이용
SELECT grade FROM student WHERE NAME='김종연');
-- 문제
-- 사원테이블에서 사원직급의 평균급여보다 적게받는
-- 직원의 사원번호 , 이름 , 직급 , 급여
SELECT AVG(salary)
FROM emp e
WHERE e.job = '사원';#557.142
SELECT e.empno , e.ename , e.job , e.salary
FROM emp e
WHERE salary < ( # 직급='사원'의 평균급여
SELECT AVG(salary)
FROM emp e
WHERE e.job = '사원');
1-2)복수행 subquery
서브쿼리의 결과가 여러개행인 경우
사용가능한 연산자 : in , <,>all , >,<any
-- emp . dept 테이블 이용해 근무지역이 서울인 사원의
# 사원번호 이름 , 부서코드 , 부서명을 조회
SELECT * FROM dept;
SELECT e.empno , e.ename , e.deptno , d.dname
FROM emp e , dept d
WHERE e.deptno = d.deptno
AND e.deptno IN (10,20,30,40);
SELECT e.empno , e.ename , e.deptno , d.dname , d.loc
FROM emp e , dept d
WHERE e.deptno = d.deptno
AND e.deptno IN (SELECT deptno FROM dept WHERE loc='서울');
# 서브쿼리의 조회결과가 여러개일경우엔 in을 사용해야함
#문제
# 1학년 학생과 같은키를 가지고있는 2학년학생의 이름 , 키 , 학년
SELECT height
FROM student
WHERE grade=1; #170,173 , 178,183
SELECT s1.NAME , s1.height , s1.grade
FROM student s1
WHERE s1.grade=2 AND s1.height IN(
SELECT height
FROM student
WHERE grade=1);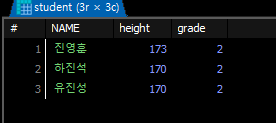
-- 사원 직급의 최대급여보다 급여가높은 직원의 이름 , 직급 , 급여조회
SELECT eNAME , job , salary
FROM emp
WHERE salary > (SELECT MAX(salary) FROM emp WHERE job='사원');
# 그닥 자주사용되지않음
-- >all : 복수결과값의 모든값보다 큰 경우 (그룹함수사용)
-- >any : 복수결과값 중 한개보다 큰 경우 (그룹함수사용)
SELECT eNAME , job , salary
FROM emp
WHERE salary > all(SELECT salary FROM emp WHERE job='사원');
-- 문제
# major 테이블에서 컴퓨터정보학부(상위)에 소속된 학생의학번 , 이름 , 학과번호
-- 학과명 출력
SELECT m.code FROM major m WHERE m.`name`='컴퓨터정보학부';#100
SELECT s.studno , s.name , m.name ,m.code '내코드', m.part'상위코드'
FROM student s , major m
WHERE m.part IN(SELECT m.code FROM major m WHERE m.`name`='컴퓨터정보학부')
AND s.major1 = m.code;
# m.part(자신의 상위 코드)
1-3) 다중컬럼 subquery
비교 대상이 2개인경우
사용 예시
-- 학년별로 최대 키를 가진 학생의 학년 이름 키 조회
#그룹함수의 이름조회는 정확하게되지않음
SELECT grade ,NAME,height ,MAX(height)
FROM student
GROUP BY grade;
#union을 이용한방법 (코드가너무길어짐)
SELECT grade,NAME,height
FROM student
WHERE grade=1 AND height in(SELECT MAX(height) FROM student WHERE grade=1)
union
SELECT grade,NAME,height
FROM student
WHERE grade=2 AND height in(SELECT MAX(height) FROM student WHERE grade=2)
union
SELECT grade,NAME,height
FROM student
WHERE grade=3 AND height in(SELECT MAX(height) FROM student WHERE grade=3)
union
SELECT grade,NAME,height
FROM student
WHERE grade=4 AND height in(SELECT MAX(height) FROM student WHERE grade=4);#다중컬럼 서브쿼리
SELECT grade , NAME , height
FROM student
WHERE (grade,height) IN
( SELECT grade,MAX(height)
FROM student GROUP BY grade )
ORDER BY grade;
-- emp테이블에서 직급별 해당 직급의 최대급여받는 직원의 정보조회
SELECT *
FROM emp e
WHERE (e.job , e.salary)IN
( SELECT job , MAX(salary)
FROM emp GROUP BY job);직급별 최대급여를 받는 직원정보

문제
학과별 입사일 가장 오래된교수의 교수번호,이름,입사일 ,학과명 조회
SELECT p.no , p.name , p.hiredate , m.name
FROM professor p , major m
WHERE (p.hiredate , p.deptno) IN
(#부서별로 그룹을 만든 후 가장작은입사일(오래된입사일)select
SELECT min(p.hiredate) , p.deptno
FROM professor p
GROUP BY deptno
)
AND p.deptno = m.code;
1-4 ) 상호연관 subquery
상호연관 서브쿼리 : 외부query 의 컬럼이 subquery에 영향을 주는 query
(성능 bad)
-- 문제
-- 교수 본인 직급의 평균급여 이상을 받는 곳의이름 , 직급 , 급여조회
SELECT POSITION , AVG(salary)
FROM professor p2
GROUP BY POSITION;
#평균급여
#시간강사247
# 정교수 466.6 , 조교수 390.3
SELECT NAME , POSITION , salary
FROM professor p1
WHERE salary >= (
SELECT AVG(salary)
FROM professor p2
WHERE p2.position = p1.`position`);
1-5) inline view subquery
-- from 구문에 사용되는 subquery --> inline 뷰 subquery
#inline뷰subquery 는 반드시 테이블의별명을 작성해야함
SELECT *
FROM
(select grade , avg(weight) avg FROM student s1 GROUP BY grade) a
WHERE AVG = (SELECT MIN(AVG)
FROM (SELECT grade,AVG(weight) AVG FROM student GROUP BY grade)a);
SELECT grade , MIN(AVG)
FROM (select grade,AVG(weight) AVG FROM student GROUP BY grade ORDER BY avg)a;
#inline뷰subquery 는 반드시 테이블의별명을 작성해야함
2) @@ DDL( 데이터정의어) @@
2-1) 자료형 (maria DB)



2-2) DDL의 특징
DDL : data definition language( 데이터정의어)
객체의 구조를 생성,수정,제거
create : 객체생성 명령어
table 생성 : create table
사용자 생성 : crate user
index 생성 : create index
drop : 객체 삭제명렁어
alter : 객체 수정 명령어(컬럼추가,삭제,컬럼크기변경,제약조건)
add , drop
truncate : 데이터제거 (객체와 데이터 분리)
DDL 의 특징 : transaction 처리 안됨(commit ,rollback X)
단계별이 아닌 한번에 데이터가들어감
ex)
계좌이체
-출금
1.출금계좌에서확인
2.출금계좌에서 잔액차감
3.출금계좌에 거래내역추가
4.회계처리
(중간에서오류발생시 모든 거래 원위치로변경: rollback)
-입금
1.입금계좌확인
2.입금계좌 잔액 증가
3.입금계좌에 거래내역 추가
4.회계처리
- 모든거래 정상 시 : commit
transaction : 최소 업무 단위
(계좌이체의경우 입금,출금이 하나의트랜잭션)
2-3) create
create table 테이블명(
컬럼명1 자료형[제약조건:기본키,auto_increment]
컬럼명2 자료형...
...
primary key (컬럼1,컬럼2) 기본키 설정
)
table 생성 명령어
사용 예)
-- no int , name varchar(20), birth datetime 컬럼을 가진 test1 테이블생성
CREATE TABLE test1 (
NO INT ,
NAME VARCHAR(20),
birth datetime
);
-- desc명령어로 스키마조회
DESC test1;
#기본키 : Primary key :각 레코드를 구분할수있는데이터(레코드의고유값)
학번 ..
기본키컬럼은 절대 중복되지않음(유일성), null값 허용X
최소의컬럼으로 만들어야한다(최소성)
#auto_increment :자동으로 1씩 증가(숫자형기본키에서만 사용가능)
오라클에서는사용할수없음 ! 오라클은 시퀀스객체를 사용함
-- no int primary key, name varchar(20), birth datetime 컬럼을 가진 test1 테이블생성
CREATE TABLE test2 (
NO INT PRIMARY KEY AUTO_INCREMENT, #제약조건
NAME VARCHAR(20),
birth datetime
);
DESC test2;
#-----다른방법으로 primary key 지정--------------
CREATE TABLE test3 (
NO INT , #제약조건
NAME VARCHAR(20),
birth DATETIME,
PRIMARY KEY(NO)
);
DESC test3;
INSERT INTO test2(NAME,birth) VALUES('홍길동','1990-01-01');
#기본키인 no은 넣지않았음
SELECT * FROM test2;
#auto_increment로 인해 자동으로 들어가는것을 확인가능
-- 기본키 컬럼을 여러개로설정하기(비추)
CREATE TABLE test4(
NO INT,
seq INT,
NAME VARCHAR(20),
PRIMARY KEY(NO,seq)
);
desc test4;
/*
no seq
1 1 가능
1 2 가능
2 1 가능
1 2 불가능(중복)
기본키는 테이블당 한개만가능(중복컬럼은가능 unique+no)
*/-- default (기본값설정)
CREATE TABLE test5(
NO INT PRIMARY KEY,
NAME VARCHAR(30) DEFAULT "홍길동"
-- 값이없으면 홍길동
);
DESC test5;
INSERT INTO test5 (NO) VALUES(1);#name은 아무것도넣지않았음
SELECT * FROM test5;
기존테이블 이용해 새로운테이블 생성하기
create table new AS select * from old;
-- dept테이블의 모든컬럼과 모든레코드를 가진 depttest1테이블 생성해보기
CREATE TABLE depttest1 AS SELECT * FROM dept;
SELECT * FROM depttest1;
#스키마확인
DESC dept;
DESC depttest1;#primary key(기본키제약조건)가 복사가 안됨depttest1 테이블 레코드 조회결과

원본(dept)

복사본(depttest1) #primary key는 복사가되지않음

-- dept 테이블의 모든컬럼과 지역이 서울인 레코드만가진
-- depttest2 테이블 생성
CREATE TABLE depttest2 AS SELECT * FROM dept d WHERE d.loc='서울';
SELECT * FROM depttest2;
레코드는 복사하지않고 컬럼명만 복사하기
-- dept 테이블의 deptno , dname 컬럼만 가지고있고
-- 레코드가없는 테이블 depttest3 생성
CREATE TABLE depttest3 AS SELECT deptno , dname FROM dept WHERE 1<0;
# where문이 거짓으로만들어야 레코드가들어가지않음(구조만 만들어짐);
SELECT * FROM depttest3;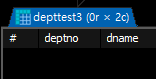
# 문제
# 교수테이블에서 101학과 교수들만 professor_101 테이블로 생성하기
-- 필요컬럼 : 교수번호 이름 학과코드 직책 학과명
CREATE TABLE professor_101 AS
SELECT p.NO , p.name , p.deptno,p.position, m.name majorname
#중복이름을 사용할수없으므로 m.name-->majorname으로 바꿔서 넘김
FROM professor p JOIN major m
ON p.deptno = m.code
WHERE p.deptno=101;as select문을 이용해 밑의 쿼리의 select문 결과를 새로운테이블에 넣는다

우리가만든 테이블이 많다
현재DB에서 테이블의 목록을 출력하는 방법
@@ SHOW TABLES;

2-4) alter
1)ALTER 컬럼 수정
1-1)컬럼 추가( ADD)
DESC depttest3;
SELECT * FROM depttest3;
#테이블구조 변경(추가)
ALTER TABLE depttest3 ADD loc VARCHAR(30);
# int형컬럼 part 추가
ALTER TABLE depttest3 ADD part INT;
DESC depttest3;
SELECT * FROM depttest3;원본

ALTER TABLE depttest3 ADD loc VARCHAR(30)
ALTER TABLE depttest3 ADD part INT 후

1-2)컬럼변경( MODIFY)
-- 문제
-- part 컬럼의 자료형을 int-> int(2) 크기변경
-- depttest3 테이블의 loc컬럼 varchar(100)크기변경
ALTER TABLE depttest3 MODIFy part INT(2);
ALTER TABLE depttest3 MODIFY loc VARCHAR(100);
DESC depttest3;
MODIFY로 변경 후 (part int(11)->int(2)
(loc varchar(30)-> varchar(100))

1-3)컬럼 삭제( DROP)
-- depttest3 테이블에 part컬럼 제거
ALTER TABLE depttest3 DROP part;
DESC depttest3;part 컬럼 제거 후 ( DROP을 통해 제거)

1-4)컬럼 변경( CHANGE)
-- depttest3테이블에 loc컬럼의 이름을 area로 변경
-- 그 후 varchar(30)으로크기 변경
ALTER TABLE depttest3 CHANGE loc AREA VARCHAR(30);
DESC depttest3;
ALTER TABLE depttest3 CHANGE area loc VARCHAR(100);#원상복구
DESC depttest3;
원상복구

1-5)ALTER 컬럼 수정 정리
컬럼관련 수정
컬럼 추가 : add 컬럼명 자료형
컬럼크기변경 : modify 컬럼명 자료형
컬럼제거 : drop 컬럼명
컬럼이름or자료형변경 : change 원본컬럼명 변경컬럼명 [자료형]
2)alter 제약조건 수정
2-1) 기본키설정
alter table 테이블명 add constraint primary key (컬럼명)
-- depttest3 테이블의 deptno컬럼을 기본키로 설정해보자
ALTER TABLE depttest3 ADD CONSTRAINT PRIMARY KEY (deptno);
DESC depttest3;
2-2) 외래키설정
alter table 테이블명 add constraint foreign key (컬럼명)
references 대상테이블 (대상컬럼);
-- 외래키 설정
-- professor_101 테이블의 no컬럼은 professor 테이블의 no컬럼을 참조하도록
-- 외래키로 설정해보자
ALTER TABLE professor_101 ADD CONSTRAINT FOREIGN KEY (NO)
REFERENCEs professor (NO);
-- professor_101 테이블에 deptno컬럼은 major 테이블의 code컬럼을 참조하도록 등록
ALTER TABLE professor_101 ADD CONSTRAINT FOREIGN KEY (deptno)
REFERENCES major(CODE);
DESC professor_101;

-- professor_101 테이블에 no가2000인 교수 추가하기
-- INSERT into professor_101 VALUES(2000,'유동곤',101,'대장','총괄부'); 오류발생
# no는 professor의 no의 외래키 --> (professor에 존재하지않는 키 삽입 불가)professor에 없는 no를 사용해 레코드값 삽입 시도

-- 문제
-- professor_101 테이블 기본키 설정
-- no 컬럼으로 기본키 설정
ALTER TABLE professor_101 ADD CONSTRAINT PRIMARY KEY(NO);
DESC professor_101;
하지만 전에 no는 외래키로 한번 설정했으므로
기본키이면서 외래키임(professor의 no 참조)
-- 하나의 테이블에 외래키는 여러개 가능
-- 하나의 테이블에 기본키는 1개만 가능
-- 제약조건 조회하기professor_101
-- 하나의 테이블에 외래키는 여러개 가능
-- 하나의 테이블에 기본키는 1개만 가능
-- 제약조건 조회하기professor_101
USE information_schema;
#db를 선택(information_schema 선택)
#information_schema 의 view를 사용할것이다
SELECT * FROM table_constraints
WHERE TABLE_NAME = 'professor_101';
USE gdjdb; #gdjdb를 사용하겠다
# DB를 직접클릭하는것과 같음
SELECT * FROM professor_101;
3) 예제
-- 1. 학년의 평균 몸무게가 70보다 큰 학년의 학년와 평균 몸무게 출력하기
SELECT grade , AVG(weight)
FROM student
GROUP BY grade
HAVING AVG(weight)>70;
-- 2. 학년별로 평균체중이 가장 적은 학년의 학년과 평균 체중을 출력하기
SELECT * #학년별 평균체중이 나올것이다
FROM(SELECT grade , AVG(weight) w FROM student GROUP BY grade
)a
ORDER BY w; # 체중의 오름차순으로 정렬해줌
SELECT grade , min(w)'평균체중'
FROM(SELECT grade , AVG(weight) w FROM student GROUP BY grade
ORDER BY w)a;
#2개의 컬럼(grade,w)을가진 student테이블을 사용한다고 생각하면 편하다
-- 3. 전공테이블(major)에서 공과대학(deptno=10)에 소속된 학과이름을 출력하기
SELECT * FROM major;
SELECT m1.code'상위코드' ,m2.code , m2.`name`
FROM major m1 , major m2
WHERE m1.code = m2.part AND m2.part=10;
-- 4. 자신의 학과 학생들의 평균 몸무게 보다 몸무게가 적은 학생의 학번과,이름과, 학과번호, 몸무게를 출력하기
SELECT studno , NAME , s1.major1 , s1.weight
FROM student s1
WHERE s1.weight < (SELECT AVG(weight) FROM student s2 WHERE s1.major1 = s2.major1);
-- 5. 학번이 220212학생과 학년이 같고 키는 210115학생보다 큰 학생의 이름, 학년, 키를 출력하기
SELECT grade FROM student s3 WHERE s3.studno=220212; #163
SELECT height FROM student s2 WHERE s2.studno=210115; #3학년
SELECT s1.name , s1.grade , s1.height
FROM student s1
WHERE height >= (SELECT height FROM student s2 WHERE s2.studno=210115)
AND grade = (SELECT grade FROM student s3 WHERE s3.studno=220212);
-- 6. 컴퓨터정보학부에 소속된 모든 학생의 학번,이름, 학과번호, 학과명 출력하기
SELECT * FROM major;
SELECT s1.studno , s1.major1 , m1.`name`
FROM student s1 , major m1
WHERE m1.part IN (SELECT part FROM major WHERE CODE=100); #컴퓨터정보학부의 code==100
-- 7. 4학년학생 중 키가 제일 작은 학생보다 키가 큰 학생의 학번,이름,키를 출력하기
SELECT MIN(height) FROM student
WHERE grade=4
GROUP BY grade; #4학년중 가장작은 학생은 163
SELECT grade,studno , NAME , height
FROM student s1
WHERE height > ( # 이 서브쿼리로 4학년중가장작은 학생의 키를 반환
SELECT MIN(height) FROM student
WHERE grade=4
GROUP BY grade);
-- 8. 학생 중에서 생년월일이 가장 빠른 학생의 학번, 이름, 생년월일을 출력하기
SELECT studno , NAME , MIN(birthday)'생년월일'
FROM student;
-- 9. 학년별 생년월일이 가장 빠른 학생의 학번, 이름, 생년월일,학과명을 출력하기
SELECT s1.grade , s1.studno , s1.NAME , s1.birthday , m.name
FROM student s1 join major m
ON s1.major1 = m.code
GROUP BY grade
HAVING MIN(birthday);
-- 10. 학과별 입사일 가장 오래된 교수의 교수번호,이름,입사일,학과명 조회하기
SELECT p.no , p.name , p.hiredate , m.`name`
FROM professor p JOIN major m
ON p.deptno = m.code
GROUP BY deptno
HAVING MIN(hiredate); #가장작은게 젤 오래된날짜임
-- 11 학년별ㄹ 평균키가 가장적은학년의 학년과 평균키출력
SELECT grade , MIN(b)
FROM(SELECT grade , AVG(height)b FROM student GROUP BY grade
ORDER BY b)a;
-- 12 학생의 학번 이름 학년 키몸무게 학년의최대키 최대몸무게조회
SELECT studno , NAME , grade , height , weight ,
(SELECT MAX(height) FROM student WHERE grade=s1.grade) 최대키,
(SELECT MAX(weight) FROM student WHERE grade=s1.grade) 최대몸무게
FROM student s1
ORDER BY grade;
-- 13 교수번호 이름 부서코드 부서명 자기부서의 평균급여 평균보너스조회
-- 보너스가없으면 0 으로처리
# select에 서브쿼리를 사용했음 (서브쿼리의 하나의 컬럼을 외부쿼리의 select문에 사용가능)
# 서브쿼리의 조건문에 외부쿼리의 deptno를 사용해서 자기부서라는 조건을 달았음
SELECT p.no , p.name , p.deptno ,
(SELECT AVG(salary)FROM professor WHERE deptno = p.deptno)'부서평균급여',
(SELECT AVG(IFNULL(bonus,0)) FROM professor WHERE deptno = p.deptno)'평균보너스',
m.name 부서명
FROM professor p , major m
WHERE p.deptno = m.code;
#문헌정보학과만 평균보너스가 0 이다 확인해보자
SELECT bonus FROM professor WHERE deptno = 301; #null
-- 14 test6 테이블생성하기
-- 컬럼 : seq :숫자 기본키 자동증가
-- name : 문자형 20문자
-- birth : 날짜만
CREATE TABLE test6 (
seq INT PRIMARY key AUTO_INCREMENT,
NAME CHAR(20),
birth DATE);
DESC test6;내가 만든 예제들
-- subquery 활용 예제만들기
-- where 절 (subquery)
# 문제 guset 의 노인우 회원보다 많은 포인트를 가진
# 회원들의 포인트로 살수있는 아이템의 갯수를 조회해봐
SELECT * FROM guest;
SELECT * FROM pointitem;
SELECT g.NAME , g.POINT , COUNT(*) 아이템갯수
FROM guest g JOIN pointitem p
ON g.`point` > p.spoint
#노인우회원보다 포인트가많은 회원대상으로
# 아이템의 시작포인트보다 큰 경우 join
WHERE POINT > (SELECT POINT #노인우회원의포인트
FROM guest
WHERE NAME='노인우')
GROUP BY g.name;
-- 다중컬럼 예제
-- student에서 학년별 가장 작은 키를 가진 학생의이름 , 키 ,학과번호
SELECT s.grade,s.name , s.height , s.major1
FROM student s
WHERE (s.grade , s.height) IN (
SELECT grade , MIN(height)
FROM student
GROUP BY grade)
ORDER BY grade;
#from절에서의 subquery
SELECT * FROM product ;
# bcode(지점)의 판매 개수가 가장작은 지점을 뽑아보자
SELECT bcode , MIN(cn)
FROM(
select bcode,COUNT(*) cn
FROM product
WHERE state=2 GROUP BY bcode
ORDER BY cn)a; #서브쿼리안에서 꼭 정렬을하자
# =====================select절에서의 서브쿼리==========
#emp에서 직급,이름,자신의급여 , 자신의 직급에서의 평균급여 , 회사에서의 평균급여 를 출력해보자
SELECT e1.job , e1.ename , e1.salary ,
(SELECT AVG(e2.salary) FROM emp e2 WHERE e1.job = e2.job) '내직급 평균급여',
(SELECT AVG(e2.salary) FROM emp e2 ) '회사 평균급여'
FROM emp e1 ;
#DDL
SELECT * from scorebase;
#student_s 테이블을 만들자
# student의 이름 학번 학년 학과 평균 학점추가해!!!
CREATE TABLE student_s AS
# s1.grade에 제약조건이존재한다 (별명을 사용해버리면제약조건이무시되므로 정상적으로 데이터가들어가지않을거임)
#제약조건이있다면 별명사용을 지양 한다.
select s1.name , s1.studno ,s1.grade ,s1.major1 ,round((s3.kor+s3.math+eng)/3) 평균, CONCAT(s2.grade,'')학점
FROM student s1 JOIN (scorebase s2 join score s3
on s2.min_point <= round((s3.kor+s3.math+eng)/3) AND s2.max_point >= ROUND((s3.kor+s3.math+eng)/3) )
on s1.studno = s3.studno;
SELECT * FROM student_s;
'부트캠프(DB)' 카테고리의 다른 글
| 부트캠프28일차 (JDBC) (0) | 2025.03.12 |
|---|---|
| 부트캠프 27일차 (DDL,DML,VIEW,사용자관리) (0) | 2025.03.11 |
| 부트캠프 25일차 (join (0) | 2025.03.07 |
| 부트캠프24일차 ( 조건함수 , 그룹함수) (1) | 2025.03.06 |
| 부트캠프23일차 (집합연산자 함수 날짜) (1) | 2025.03.05 |