1.List vs Set

정의**: 리스트는 요소들의 순차적인 컬렉션이다. 요소들은 특정 순서를 가지며, 같은 요소가 여러 번 나타날 수 있다.
**특징**:
**순서 유지**: 리스트에 추가된 요소는 특정한 순서를 유지한다. 이 순서는 요소가 추가된 순서를 반영할 수 있다.
**중복 허용**: 리스트는 동일한 값이나 객체의 중복을 허용한다. 예를 들어, 같은 숫자나 문자열을 리스트 안에 여러번
저장 할 수 있다.
**인덱스 접근**: 리스트의 각 요소는 인덱스를 통해 접근할 수 있다. 이 인덱스는 보통 0부터 시작한다.
**용도**: 순서가 중요하거나 중복된 요소를 허용해야 하는 경우에 주로 사용된다.

**정의**: 세트(셋)는 유일한 요소들의 컬렉션이다. 참고로 세트보다는 셋으로 많이 불린다.
특징
**유일성**: 셋에는 중복된 요소가 존재하지 않는다. 셋에 요소를 추가할 때, 이미 존재하는 요소면 무시된다.
**순서 미보장**: 대부분의 셋 구현에서는 요소들의 순서를 보장하지 않는다. 즉, 요소를 출력할 때 입력 순서와
다를 수 있다.
**빠른 검색**: 셋은 요소의 유무를 빠르게 확인할 수 있도록 최적화되어 있다. 이는 데이터의 중복을 방지하고
빠른 조회를 가능하게 한다.
**용도**: 중복을 허용하지 않고, 요소의 유무만 중요한 경우에 사용된다.
**예시**:
List: 장바구니 목록, 순서가 중요한 일련의 이벤트 목록.
Set: 회원 ID 집합, 고유한 항목의 집합.
직접구현하는 Set
Set은 중복을 허용하지 않고, 순서를 보장하지 않는 자료 구조이다.*
최대한 간단히 구현해보자
package collection.set;
import java.util.Arrays;
public class MyHashSetV0 {
private int[] elementData = new int[10];
private int size = 0;
// O(n)
public boolean add(int value) {
if (contains(value)) {
return false;
}
elementData[size] = value;
size++;
return true;
}
// O(n)
public boolean contains(int value) {
for (int data : elementData) {
if (data == value) {
return true;
}
}
return false;
}
public int getSize() {
return size;
}
@Override
public String toString() {
return "MyHashSetV0{" +
"elementData=" + Arrays.toString(Arrays.copyOf(elementData,
size)) +
", size=" + size +
'}';
}
}예제에서는 단순함을 위해 배열에 데이터를 저장한다. 배열의 크기도 10으로 고정했다.
`add(value)` : 셋에 중복된 값이 있는지 체크하고, 중복된 값이 있으면 `false` 를 반환한다. 중복된 값이 없으면
값을 저장하고 `true` 를 반환한다.
`contains(value)` : 셋에 값이 있는지 확인한다. 값이 있으면 `true` 를 반환하고, 값이 없으면 `false` 를 반환
한다.
`toString()` : 배열을 출력하는 부분에 `Arrays.copyOf()` 를 사용해서 배열에 데이터가 입력된 만큼만 출력
한다.
데이터를 추가할 때마다 중복 데이터가 있는지 체크하기 위해 셋의 전체 데이터를
확인해야 한다. 이때 O(n)으로 성능이 떨어진다.
해시 알고리즘 -1
해시알고리즘을 사용하면 조회를 o(1)로 끌어올릴 수 있다.
해쉬알고리즘 이해를 위해 몇가지 예제를 해보자
**문제**
입력: 0~9 사이의 여러 값이 입력된다. 중복된 값은 입력되지 않는다.
찾기: 0~9 사이의 값이 하나 입력된다. 입력된 값 중에 찾는 값이 있는지 확인해보자.
public class HashStart1 {
public static void main(String[] args) {
Integer[] inputArray = new Integer[4];
inputArray[0] = 1;
inputArray[1] = 2;
inputArray[2] = 5;
inputArray[3] = 8;
System.out.println("inputArray = " + Arrays.toString(inputArray));
int searchValue = 8;
//4번 반복 O(n)
for (int inputValue : inputArray) {
if (inputValue == searchValue) {
System.out.println(inputValue);
}
}
}
}8이란 ㄴ값을 찾으려면
모든 배열을 뒤져서 찾아야함 (성능 O(n))
해쉬알고리즘 -index

저장하는 값을 인덱스와 맞추면 어떻게 될까??
검색기능이 o(1)이 되지 않을까??
**문제**
입력 값의 범위 만큼 큰 배열을 사용해야 한다. 따라서 배열에 낭비되는 공간이 많이 발생한다. 이 문제를 더 알아보자.
해시알고리즘 - 메모리낭비
**문제**
입력: **0~99** 사이의 여러 값이 입력된다. 중복된 값은 입력되지 않는다.
찾기: **0~99** 사이의 값이 하나 입력된다. 입력된 값 중에 찾는 값이 있는지 확인해보자.
public class HashStart3 {
public static void main(String[] args) {
Integer[] inputArray = new Integer[100];
inputArray[1] = 1;
inputArray[2] = 2;
inputArray[5] = 5;
inputArray[8] = 8;
inputArray[99] = 99;
System.out.println("inputArray = " + Arrays.toString(inputArray));
int searchValue = 8;
int result = inputArray[searchValue];
System.out.println("result : "+result);
}}
문제점 : 나머지 데이터가들어있지 않은 인덱스가
모두 null값으로 채워져 메모리낭비가 심함
해시알고리즘 - 나머지연산
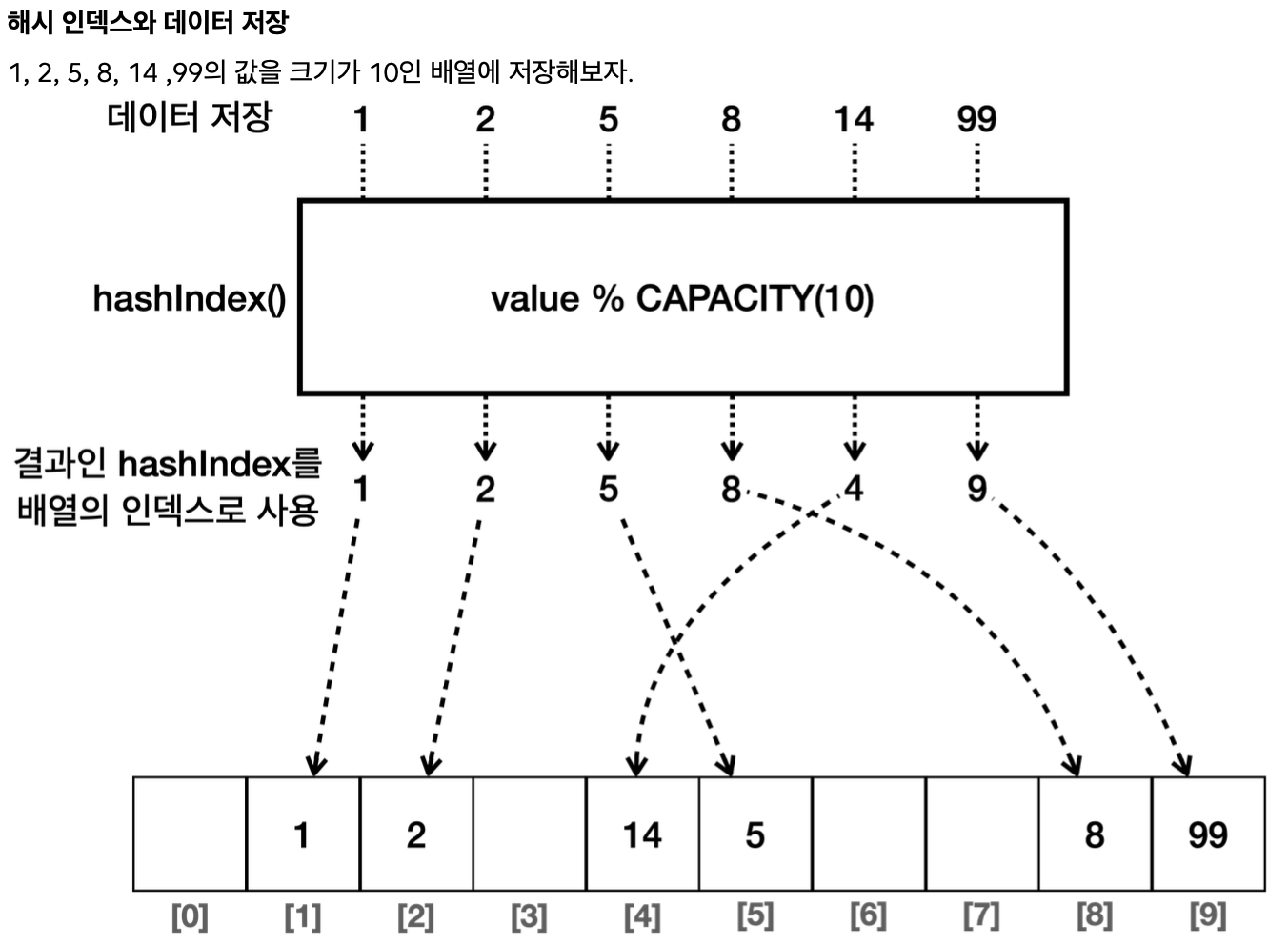
저장할 수 있는 배열의 크기(CAPACITY)를 10이라고 가정하자. 그 크기에 맞추어 나머지 연산을 사용하면 된다.
나머지 연산
`1 % 10 = 1`
`2 % 10 = 2`
`5 % 10 = 5`
`8 % 10 = 8`
`14 % 10 = 4`
`99 % 10 = 9`
해시 인덱스
이렇게 배열의 인덱스로 사용할 수 있도록 원래의 값을 계산한 인덱스를 해시 인덱스(hashIndex)라 한다.
14의 해시 인덱스는 4, 99의 해시 인덱스는 9이다.
코드로 구현해보자
package collection.set;
import java.util.Arrays;
public class HashStart4 {
static int CAPACITY = 10;
public static void main(String[] args) {
//{1, 2, 5, 8, 14, 99}
System.out.println("hashIndex(1) = " + hashIndex(1));
System.out.println("hashIndex(2) = " + hashIndex(2));
System.out.println("hashIndex(5) = " + hashIndex(5));
System.out.println("hashIndex(8) = " + hashIndex(8));
System.out.println("hashIndex(14) = " + hashIndex(14));
System.out.println("hashIndex(99) = " + hashIndex(99));
Integer[] inputArray = new Integer[CAPACITY];
add(inputArray, 1);
add(inputArray, 2);
add(inputArray, 5);
add(inputArray, 8);
add(inputArray, 14);
add(inputArray, 99);
System.out.println("inputArray = " + Arrays.toString(inputArray));
//검색
int searchValue = 14;
int findHashIndex = hashIndex(searchValue);
System.out.println("searchValue hashIndex = " + findHashIndex);
Integer result = inputArray[findHashIndex]; // O(1)
System.out.println("result : "+result);
}
private static void add(Integer[] inputArray, int value) {
int hashIndex = hashIndex(value);
inputArray[hashIndex] = value;
}
static int hashIndex(int value) {
return value % CAPACITY;
}
}출력결과
hashIndex(1) = 1
hashIndex(2) = 2
hashIndex(5) = 5
hashIndex(8) = 8
hashIndex(14) = 4
hashIndex(99) = 9
inputArray = [null, 1, 2, null, 14, 5, null, null, 8, 99]
searchValue hashIndex = 4
result : 14
**한계 - 해시 충돌**
그런데 지금까지 설명한 내용은 저장할 위치가 충돌할 수 있다는 한계가 있다.
예를 들어 1, 11의 두 값은 이렇게 10으로 나누면 같은 값 1이 된다. 둘다 같은 해시 인덱스가 나와버리는 것이다.
`1 % 10 = 1`
`11 % 10 = 1`
해시알고리즘 - 해시충돌설명

해시 충돌 해결
해시 충돌을 인정하면 문제 해결의 실마리가 보인다.
해시 충돌은 낮은 확률로 일어날 수 있다고 가정하는 것이다.
해결 방안은 바로 해시 충돌이 일어났을 때 단순하게 같은 해시 인덱스의 값을 같은 인덱스에 함께 저장!

해시알고리즘 - 해시충돌 구현
package collection.set;
import java.util.Arrays;
import java.util.LinkedList;
public class HashStart5 {
static final int CAPACITY = 10;
public static void main(String[] args) {
//{1, 2, 5, 8, 14, 99 ,9}
LinkedList<Integer>[] buckets = new LinkedList[CAPACITY];
for (int i = 0; i < CAPACITY; i++) {
buckets[i] = new LinkedList<>();
}
add(buckets, 1);
add(buckets, 2);
add(buckets, 5);
add(buckets, 8);
add(buckets, 14);
add(buckets, 99);
add(buckets, 9); //중복
System.out.println("buckets = " + Arrays.toString(buckets));
//검색
int searchValue = 9;
boolean contains = contains(buckets, searchValue);
System.out.println("buckets.contains(" + searchValue + ") = " +
contains);
}
private static void add(LinkedList<Integer>[] buckets, int value) {
int hashIndex = hashIndex(value);
LinkedList<Integer> bucket = buckets[hashIndex]; // O(1)
if (!bucket.contains(value)) { // O(n)
bucket.add(value);
}
}
private static boolean contains(LinkedList<Integer>[] buckets, int
searchValue) {
int hashIndex = hashIndex(searchValue);
LinkedList<Integer> bucket = buckets[hashIndex]; // O(1)
return bucket.contains(searchValue); // O(n)
}
static int hashIndex(int value) {
return value % CAPACITY;
}
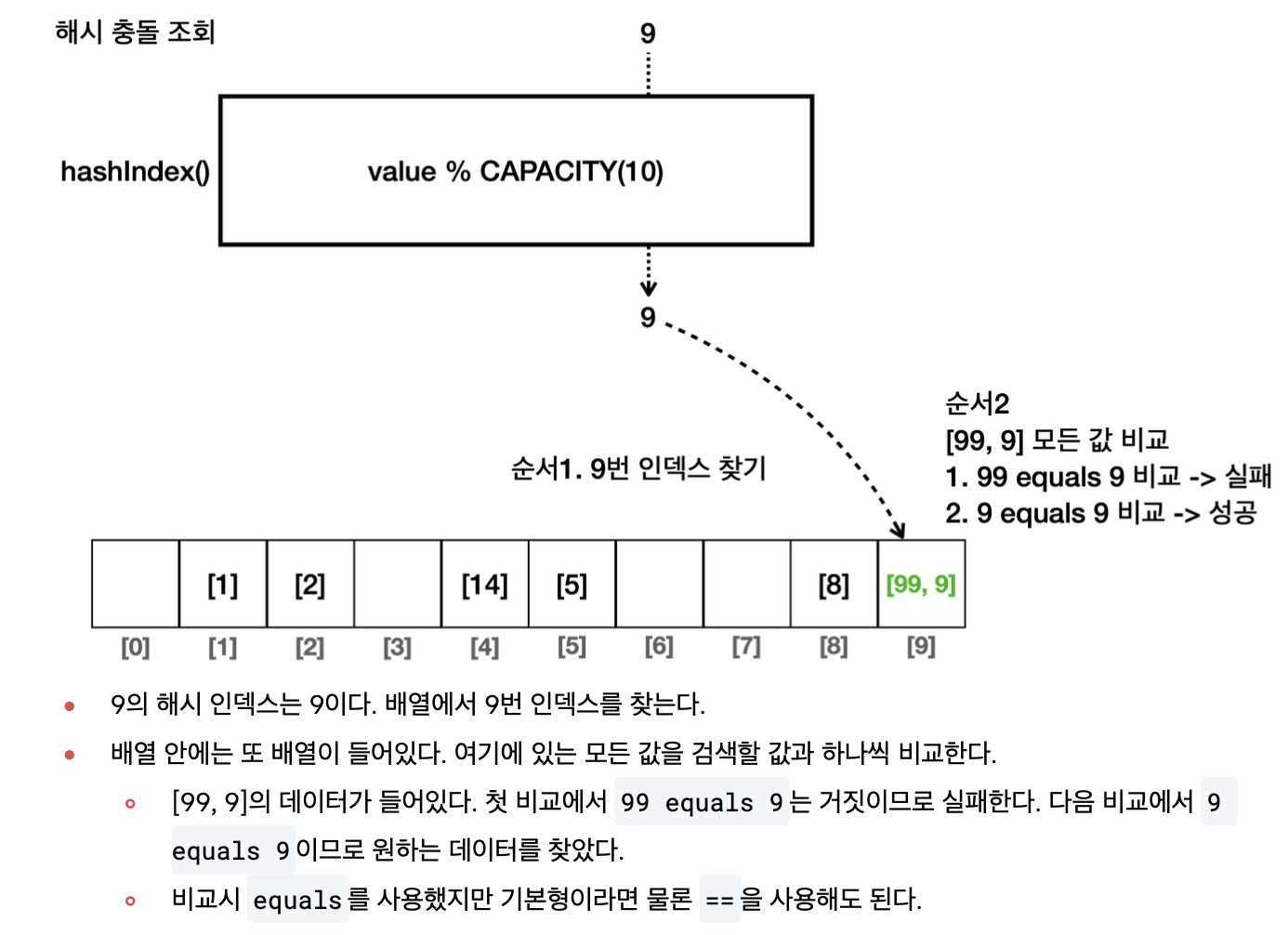
}실행 결과**
buckets = [[], [1], [2], [], [14], [5], [], [], [8], [99, 9]]
bucket.contains(9) = true
배열 안에 연결 리스트가 들어있고, 연결 리스트 안에 데이터가
들어가는 구조이다.
데이터 등록**
```java
private static void add(LinkedList<Integer>[] buckets, int value) {
int hashIndex = hashIndex(value);
LinkedList<Integer> bucket = buckets[hashIndex]; //O(1)
if (!bucket.contains(value)) { //O(n)
bucket.add(value);
}
}데이터를 등록할 때 먼저 해시 인덱스(hashIndex)를 구한다.
해시 인덱스로 배열의 인덱스를 찾는다. 배열에는 연결 리스트가 들어있다.
해시 인덱스를 통해 바구니들 사이에서 바구니인 연결 리스트를 하나 찾은 것이다.
셋은 중복된 값을 저장하지 않는다. 따라서 바구니에 값을 저장하기 전에 `contains()` 를 사용해서 중복 여부를
확인한다. 만약 바구니에 같은 데이터가 없다면 데이터를 저장한다.
연결 리스트의 `contains()` 는 모든 항목을 다 순회하기 때문에 O(n)의 성능이다.
하지만 해시 충돌이 발생하지 않으면 데이터가 1개만 들어있기 때문에 O(1)의 성능을 제공한다.
데이터검색
private static boolean contains(LinkedList<Integer>[] buckets, int searchValue){
int hashIndex = hashIndex(searchValue);
LinkedList<Integer> bucket = buckets[hashIndex]; //O(1)
return bucket.contains(searchValue); //O(n)
}연결 리스트의 `bucket.contains(searchValue)` 메서드를 사용해서 찾는 데이터가 있는지 확인한다.
연결 리스트의 `contains()` 는 모든 항목을 다 순회하기 때문에 O(n)의 성능이다.
하지만 해시 충돌이 발생하지 않으면 데이터가 1개만 들어있기 때문에 O(1)의 성능을 제공한다.

**CAPACITY = 10**: 저장할 데이터가 7개 인데, 배열의 크기는 10이다. **7/10 약 70% 정도**
로 약간 여유있게 데이
터가 저장된다. 이 경우 가끔 충돌이 발생한다.
**CAPACITY = 11**: 저장할 데이터가 7개 인데, 배열의 크기는 11이다. 가끔 충돌이 발생한다. 여기서는 충돌이
발생하지 않았다.
**CAPACITY = 15**: 저장할 데이터가 7개 인데, 배열의 크기는 15이다. 가끔 충돌이 발생한다. 여기서는 충돌이
하나 발생했다.
통계적으로 입력한 데이터의 수가 배열의 크기를 75% 넘지 않으면 해시 인덱스는
자주 충돌하지 않는다. 반대로 75%를 넘으면 자주 충돌하기 시작한다.
'Java공부(코딩)' 카테고리의 다른 글
| 코딩초보의 자바(Java)공부 29일차 - { Set } (1) | 2025.01.15 |
|---|---|
| 코딩초보의 자바(Java)공부 28일차 { HashSet } (0) | 2025.01.14 |
| 코딩초보의 자바(Java)공부 26일차 { 컬렉션프레임워크 - List } (0) | 2025.01.09 |
| 코딩초보의 자바(Java)공부 25일차 { 컬렉션프레임워크 - ArrayList와LinkedList } (0) | 2025.01.08 |
| 코딩초보의 자바(Java)공부 24일차 { 제네릭 - Generic 2} (0) | 2025.01.08 |